年度明け最初の週末に向けた2018/4/6(金)の夕方、比較的広い範囲のOffice 365の一部テナントでログインに関連する障害が発生しました。
幸か不幸か、私の個人用のテナントや会社で使っているテナントは影響を受けていなかったのですが、色々と気づくことも有ったのでメモ代わりに記しておきたいと思います。
一番最初に気がついたのは、17:36にFacebookのOffice 365コミュニティに書き込まれた書き込みでした。(ちなみに、このグループは2018年4月現在1600名以上の参加者のいる私の知る限り日本最大のOffice 365ユーザーコミュニティです)
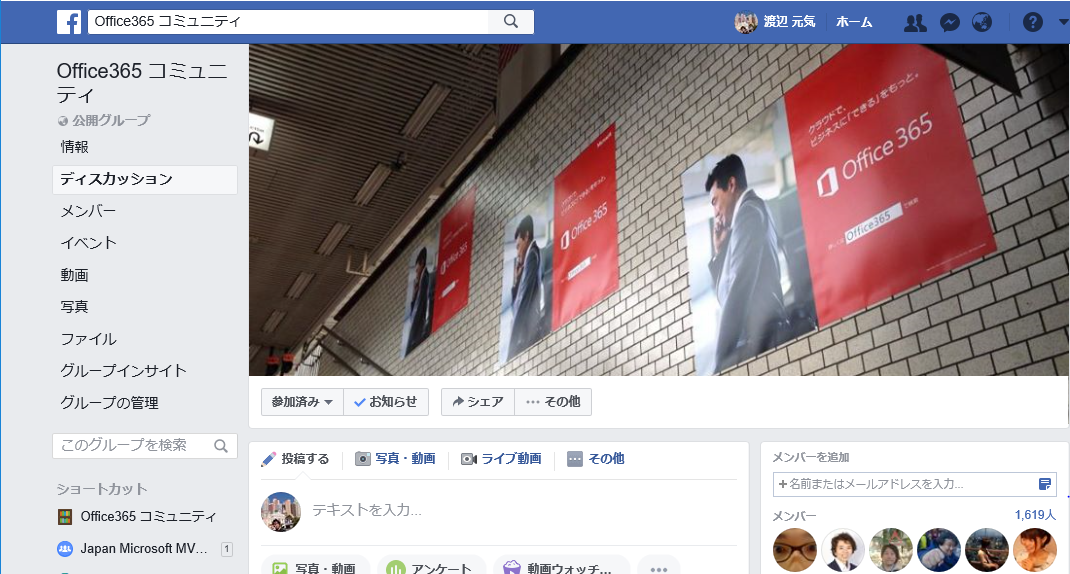
クラウドサービスの障害の対応を考えるときに最初にやることはその事象が自分だけなのか、他のテナントもなのかの切り分けです。こういった時にFacebookコミュニティは非常に有用です。1回書くと、恐らく数十のテナントで同様の障害が発生しているかどうかを参加者の方がテストしてくれると思います。
サービス正常性ダッシュボードを最初に見るように言われたり、いきなりサポートリクエストを送信するようにしているケースも有りますが、以下の様な問題点があるので、迅速な対応をしたい場合は自力でのある程度の切り分けを推奨します。
- サービスの障害としてMicrosoftが認識するトリガーは、複数のユーザーからの同様の障害申告(よって、テナント固有の問題は除外されるし、少しタイムラグがある)
- そもそもログインしないと見れないサイト上にサービス正常性が表示されている
- 通常のサポートリクエストの手順は管理者としてログイン後の物であり、電話番号や契約情報をメモっていない限りは電話での依頼はできない
そうこうしているうちに、他のユーザーから 17:40にも同様の書き込みが行われ、どうやら障害っぽような雰囲気になってきました。Twitterでも検索すると同様の書き込みが散見され出しました。日本以外のAPACやオセアニアからも同様の書き込みがされています。
この辺のサイトでヒートマップとかも表示されていて参考になりました。
Outage Report
また、エラーの発生しているユーザーからの情報で、エラーの内容は、[フェデレーションドメイン名はシステムに存在しません][サブスクリプションが見つかりません]などという物。かなり根が深そうな印象でした。
さて、皆さんご承知の通り、JapanやAustraliaはOffice 365的には Go Local というGeoであり、APACのAzure ADの張り出しみたいな形で実装されています。この為、この時点でAPACのAzure ADがおかしいのかな、と思い始めます。
注)後にEU側からも同様な報告が来ていたので、たまたまタイムゾーン的な話でAPACの報告が多かったようです
たまたま今回の障害はログイン出来るテナントがあったので確認をしたところ、サービス正常性ダッシュボードに障害の情報が掲載されていたことを確認。この時点で発生時から既に1時間ほど経過していましたが、まだ原因が特定されていなかったので、結構時間が掛かってるなという印象。
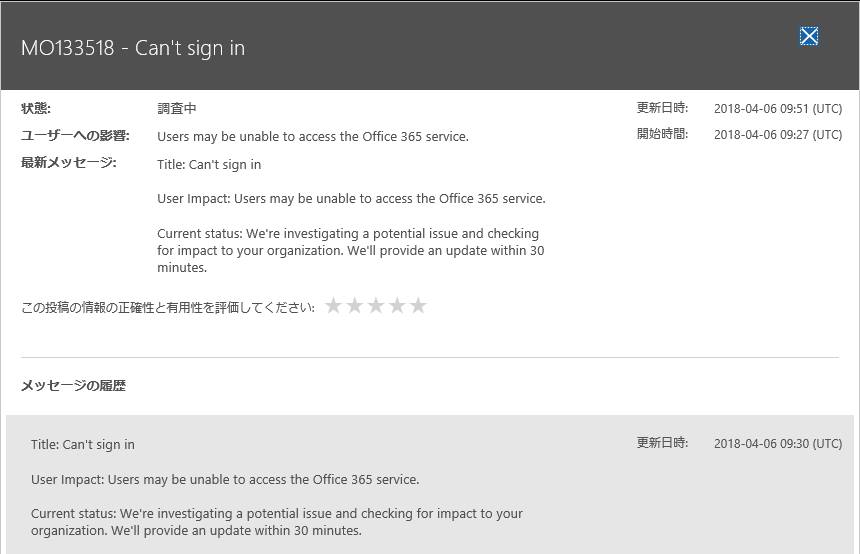
ここまで来ると、もう各ユーザーテナント側でできることはありません。社内向けに何か情シスが求められたとしても
『Office 365で、アジアを中心に一部のテナントでログインできないという障害が発生中。Microsoft側の対応を待っています。』
程度流しておくしかできないです。回復見込みはいつだ、定期報告しろ、根本原因は?とか騒ぐような方がいるような組織の場合はご愁傷様です、ユーザ側にこれ以上できることは根本的には無いのです…。
そうこうしているうちに20:08頃よりサインインできるようになったとか、サインイン出来るけどTeamsはまだとかそういった情報が流れるようになって来ました。20:30頃には大体収まったような感じでしょうか。
平行して、TwitterではMicrosoftの公式アカウントである Office 365 Status から状況の報告が出てました。今回の場合、サービス正常性ダッシュボードが確認出来ないので、こう言った広報手段というのは普段から確保しているのでしょうね。ちなみに、18:18初報、20:53終了報なので、少しタイムラグが有りそうです。
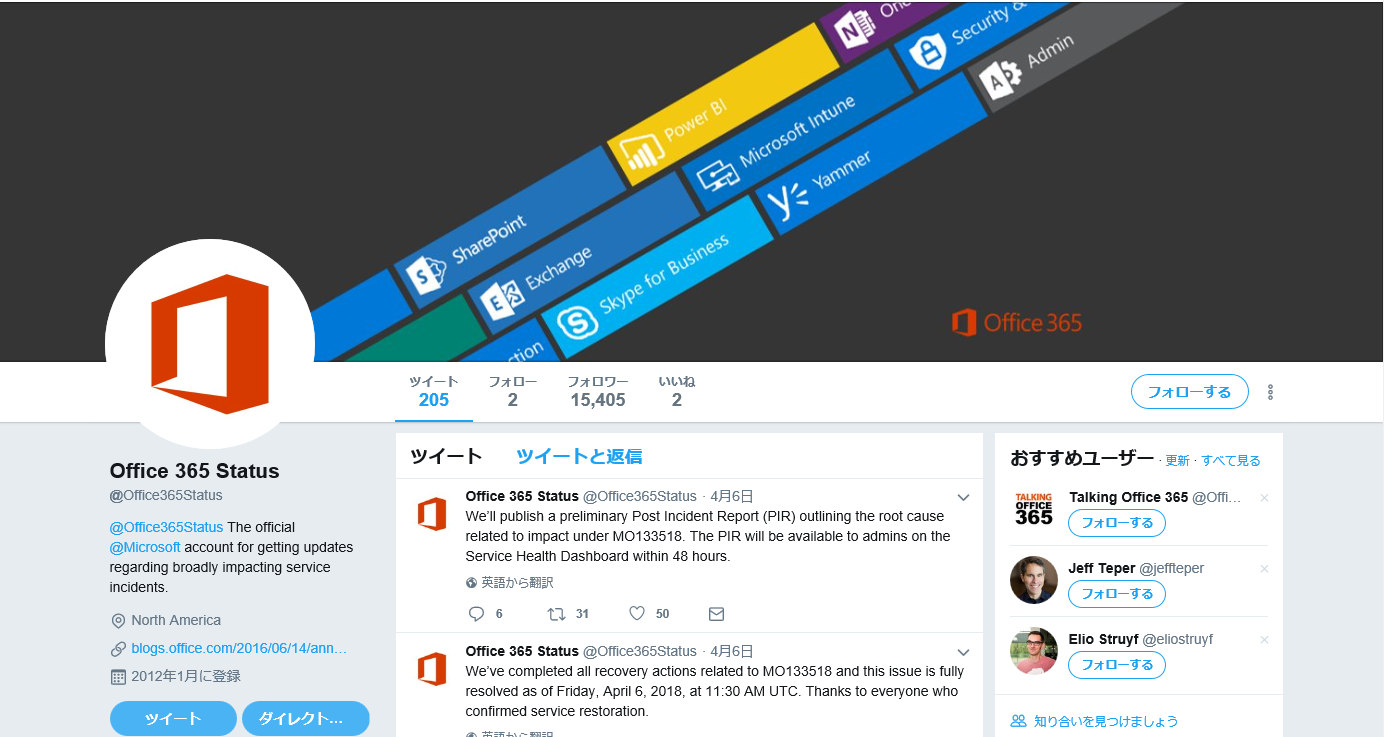
今後もこのアカウントでの告知は平行して行われるようですので、フォローしていない人はフォローしておいた方が良いかもしれませんね。
というわけで。実質3時間ほど一部テナントに影響するインシデントが発生したわけですが、認証系というかなり根が深い部分で障害だったにも関わらず、障害の認識から回復までの時間は短い方だったと思います。
PIR(事後インシデントレポート)を見る限りは根本原因はメンテナンス作業に伴う設定ミスですが、直そうとしている方向性が「①例え設定ミスしても検知できるトレンド分析」「②ユーザーからの申告より先に障害に気付ける仕組み作り」であるのは、同じクラウドサービスのサービス提供事業者として個人的に好感が持てました。
どうしても日本の企業だと、「なぜユーザー通知無しでメンテナンスを行うのか」「なぜまだ業務時間内なのにメンテナンスするのか」「そもそも何で設定ミスしたのか」などというユーザーからの直の声をそのまま対策にも反映させてしまいがちですが、正直そんなところはもう何百何千と考えて品質向上を実行してきたのでしょうからね。