登録キャンペーンによる先進的で強力な認証の推進 | Japan Azure Identity Support Blog (jpazureid.github.io) でも案内されていますが、Entra ID の登録キャンペーン(より強力な多要素認証として Microsoft Authenticator のインストールをユーザーに依頼する管理者機能)が既定で有効化されはじめてます。
従来より、SMSや電話番号での認証は相対的にセキュリティレベルが低く、Microsoft からは非推奨になっていましたのでこの機能自体は良い物だと考えているのですが、環境によっては注意が必要なケースがありますので紹介します。
そもそもこの機能は 2 年近く前から存在していて、管理者により有効化することができたのですが、今回の変更によって「①既定で有効化される」「②ユーザー判断でスキップできる回数に上限が設定される」ことになりました。
有効になった状態でログインし、電話での多要素認証を実施すると、以下の様な画面になります。[次へ] を押すと Microsoft Authenticator の設定画面に推移し、[今はしない] を押すと通常のログイン後の画面に推移します。

ポイントとしては、[今はしない] というのは3回しか押すことができないということです。
特に注意が必要なのは、以下の様なシナリオです。
- 組織に存在している管理者アカウントが 1 つしか存在しない
- 利用環境や社内の規程上 Microsoft Authenticator を利用できない(スマートフォン持ち込み不可の場所でしか利用できないなど)
- たまにしか使っていない
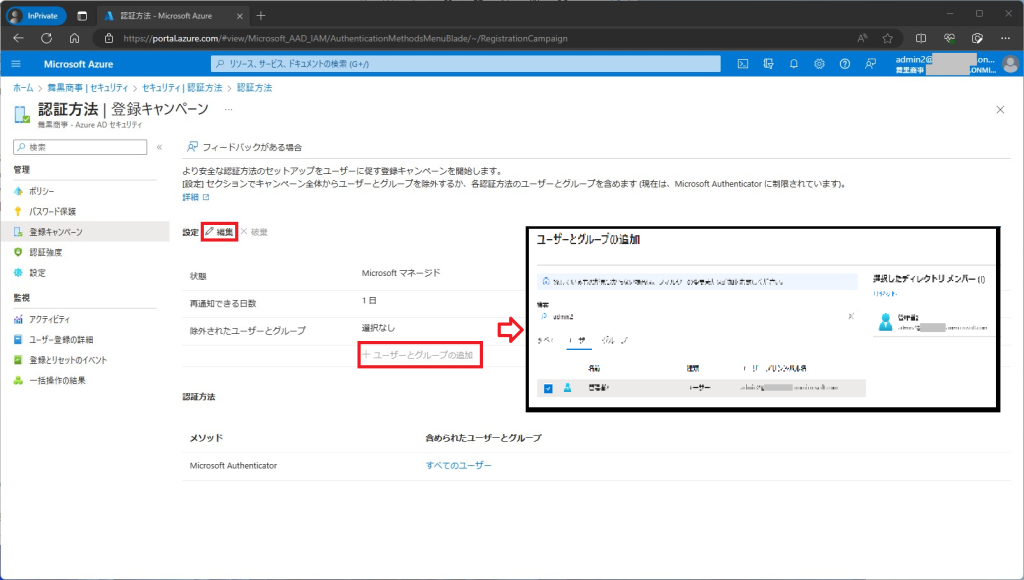
これらに該当する場合は、3回スキップする前に以下の画面で Microsoft Authenticator が利用できない環境のユーザー(今回の例だと、唯一の管理者アカウント)を登録キャンペーンから除外するという設定を入れてください。
※対象が不特定多数の場合は、状態を [Microsoftマネージド] から [無効] にして組織全体で無効化することも可能です
 Azure管理ポータル
Azure管理ポータル
[Azure Active Directory] – [セキュリティ] – [認証方法] – [登録キャンペーン]
ただ、前述の通り SMS や電話での多要素認証はセキュリティレベルが低く、既に非推奨となっております。Microsoft Authenticator が利用できない環境でも安全に多要素認証が利用できる OTP デバイスや FIDO2 セキュリティキーなどが手頃な価格で市場でも出そろってきておりますので、これを機にご検討いただくことも良いのでは無いかと思います。
また、不幸にも既に 3 回スキップしてしまった場合は、内部調整の上、特例で一度だけMicrosoft Authenticator を登録して貰ってログイン後、上記で登録キャンペーンの無効化とMFA情報から削除を実施するか、あるいは Microsoft サポートに連絡して対処を依頼して下さい。(本人確認などで時間はかかると思いますが)
3回スキップすると、次回から以下の画面から [次へ] を押して Microsoft Authenticator をインストールしないと先に進めなくなります。