この記事は Office 365 Advent Calendar 2019 に参加しています
2019年の11月18日と19日、Office 365でExchange OnlineとTeamsを中心とした大規模な障害が立て続けに発生しました。
数日後、Blogサイトに設置してある Google Analytics経由で以下の様な通知メールが来ました。
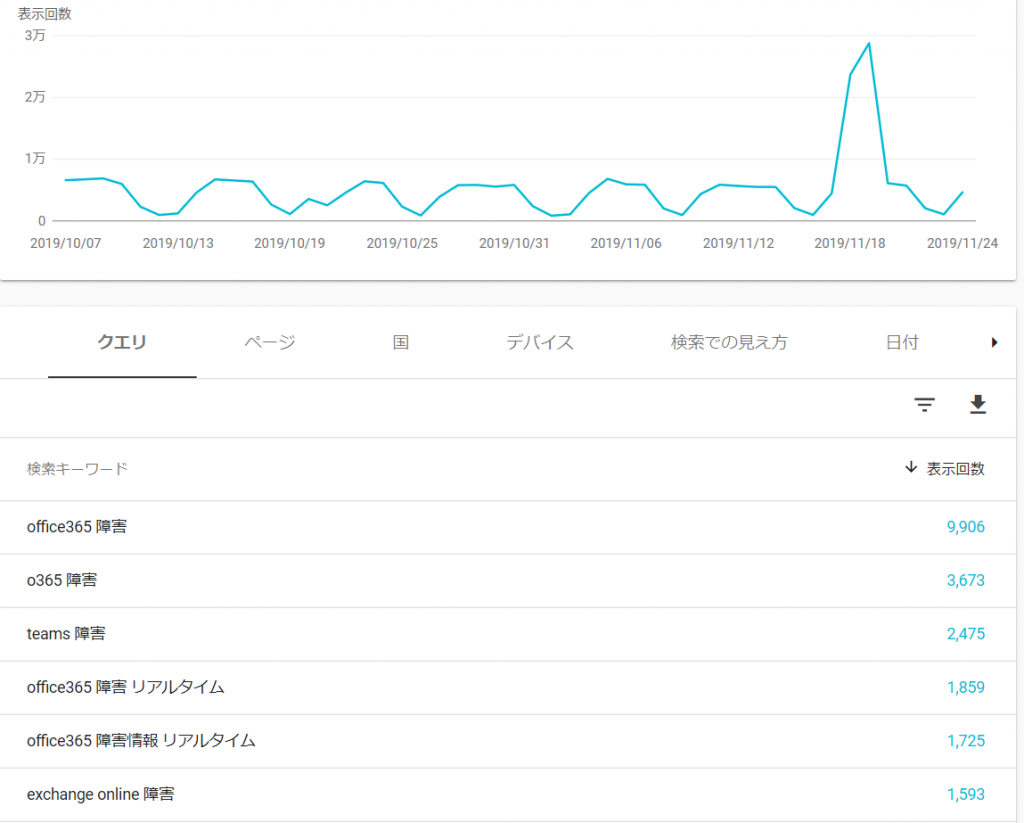
サイトにログインしてみると、確かに18日と19日に普段の5倍近いのアクセスが来ているようです。
Office 365の障害に関しての情報を有用だと感じている方も多いようですので、既にソーシャルで色々な意見も出ていましたが、今回は私のOffice 365サービスの品質に関して感じていることを項目毎にいくつか書いてみたいと思います。
なお、なるべくエビデンスを示しつつ書こうと思ったのですが、古い記事などで見当たらなくなった物も多く、私の記憶を頼りに書いている部分も多いです。誤っている項目に関しては直ちに修正させて頂きますのでご指摘頂けると幸いです。
凄いと思っていること
私自身、クラウド事業者で似たようなHostedクラウド(Exchange Server、SharePoint Server、Skype for Business Server)の開発運用に携わっていますが、ここはどうしても敵わないと思っていることがいくつかあります。
まず、基本的に全て自分で作っていること。ベースのクラウドも、そこで動くOSも、その上で動かすアプリケーションも自分たちで作って管理しているというのは有事の時の対応速度や、品質向上の観点からすると天と地ほどの差があります。
以前は、Office 365も月に1度だったり主立った物は 3ヶ月に1度の更新頻度でしたので、バグが見つかってもその次の更新のタイミングに合わせないと…などが有りましたが、今は全体に影響の出るような物は随時修正、更新されています。
また、「誤っていたら直す」「より正しい物が出てきたらそれに変更する努力をいとわない」という体質も凄いと感じてます。
具体的に言うと、例えば私の記憶では Exchange Online は最初リリース時はシンガポールDCがメインのデータセンタで、香港DCはバックアップセンタとして位置づけられていたと思います。
サービスイン当初は、シンガポールDCが
- 207.46.4.128/25
- 207.46.58.128/25
- 207.46.198.0/25
- 207.46.203.128/26
だったのに対して、香港DCは
- 111.221.69.128/25
のCIDRだけ利用していました。開始半年くらいして、影響がないと想定していたネットワーク作業でサービス影響がでました。こちら、恐らくプライマリDCからバックアップDCへの切り替えの試験を裏でしていたと思うのですが、主にDNS回りなどで想定外の事象になったようです。
その後、Exchange Onlineはシンガポールと香港を 50:50 で両 Active として利用するようになり、障害やメンテナンスに起因したデータセンタの切り替わりもシームレスに行われるようになりました。(オンプレミスの Exchange Server も同様の設計にすることがベストプラクティスになりました。)
また、同じく初期の方の障害の中でデータセンタ内部での大規模なネットワーク障害がありました。細かいメカニズムは説明されませんでしたが、L2ドメインの制御に起因する障害のようで、その後の構成変更でL2ドメインを極小化する施策をとりました。
既に何百万ユーザーもいた中で、この規模の根幹からのアーキテクチャ変更を基本的にダウンタイム無しで行うことができたというのは本当に凄いことだと思います。
日本企業で同じ事をやろうとすると、そもそも社内でも止められるケースが多いでしょうし、いざやろうとメンテナンス通知を出したとしても、お客様から「今の状態に満足しているからそんなリスクのあることして変更しないでくれ」という強い要求が来て押し切られてしまう、仕方なく「このサービスは何とかこの構成で乗り切って、次期サービスは新しいアーキテクチャでやろう」となるケースが多いのではないかと。
Microsoftも、BPOS → Office 365と3年周期で来たところでしたので、また3年で新しいブランドを作ってそちらで実現するという選択肢もあったかと思うのですが、「Office 365」というブランドで今後もずっと継続して行きたい、継続的に改善・改良を繰り返して行きたいという強い意志を感じました。
最後に、SLA がきちんとしていること。これは、単なる努力目標&返金規定として機能しているのではなく、ユーザーとの間で現実的に達成可能な数値として定められている点です。
こちら、特に Microsoft Azure の SLA の方が顕著ですが、おそらく「何でこの稼働率を保証できるのか」と聞かれた場合に、 Microsoft はかなり明確にそれを如何に達成できるのかというのを論理的に説明ができるのだと思います。この為、達成できなかった場合の返金率は日本の企業の物に比べると高いです。
| 月間稼働率 | サービスクレジット(返金率) |
| 99.9%未満 | 25% |
| 99%未満 | 50% |
| 95%未満 | 100% |
ちなみに、今回は Exchange Online の方はきっと99%未満になると思うのですが、結構な財務インパクトですね。これだと本気で品質改善しようと思うでしょうね。
余談ですが、日本のホスティング事業者は例えお客様と合意したSLAの範囲内の故障でも、画一的に決められた影響数と影響時間に基づき、障害発生時に総務省報告の義務があります。大規模障害時はお客様対応も勿論非常に大変なのですが、この監督官庁対応も非常に大変な稼働の発生するお仕事です。
なので、正直どうせ完璧を目指す再発防止策を出し続けないといけないなら、 SLAを非常に高い数字にしてしまって、万一の場合は返金すれば…と思って、例えば稼働率 100%の SLA を定めるというのも少し仕方ないかなという気もします。
ただ、ソフトウェアを使っているので、勿論想定外のバグは発生する物であり、その想定発生率が0%、例え発生したとしても100%冗長化の切り替えが成功するという前提はちょっと苦しいですよね。
ここは改善して欲しいと思っていること
色々と問題が発生する度に徐々に良くなってきているので、正直あまり残っていないのですが、少しだけ書きます。
まず、障害の認識のトリガーがですが、自社で設定したモニタリングで引っかからず、複数ユーザーからの障害申告をもって障害検知しているケースがまだ結構あると感じています。
申告に関しても「複数のユーザーからの」という条件が未だにあるらしく、今回の Exchange Online の障害に関しても、結果として発生から検知・アナウンスまで結構な(個人的な感覚で1時間以上)タイムラグがあったのではないかと思っています。
正直、その辺のデータは一杯取っているのでしょうから、地域毎のコールセンターのコール数、サポートリクエストの起票数、Web(BingやGoogle)の検索数、Twitterなどのソーシャルの発言のトレンドから「何か起こっているかも」の兆候も見いだすことができるでしょうし、RPAなどを活用して、より広い範囲で End-to-End のクライアント接続試験なども行う事ができるのはないかと期待しています。
また、メンテナンスや構成変更などの実行時間についてですが、以前は告知はしないものの、タイムゾーン毎に毎週金曜日の夜間帯がメンテナンスウィンドウとして定められていて、その時間に更新していたような記憶があります。
よくサポートリクエストの調査結果から、クラウド側のバグであることが分かったケースも、修正プログラムは完成したが、全世界に適用するまでに2-3週間かかると言われるケースなどもあり、そういった決まった短い時間だけだと対応が難しいのかも知れませんが、何か有った場合の検知やその切り戻しを迅速にする意味からもクラウド内への適用はもう少し安全かつ迅速にできる仕組みにしていって欲しいですね。
「障害かな」と思ったら自分でやっていること
今回の障害発生時に、自分でやった動作の振り返りです。
- 検証環境、もしくは別PCや別ブラウザから再現試験を実施してみて「影響範囲」「発生条件」「再現性の有無」を確認する
- サポートリクエストを上げる準備をする
- Twitterで似たような症状のつぶやきが無いか検索する(例: 「Office365」「メール」「遅延」)
- 自分でもつぶやく
- FacebookのOffice365コミュニティを見る
- 正常性ダッシュボード([サービスの正常性])を見る
- サポートリクエストを上げる
今回は、Teamsの障害の方は [サービスの正常性] ごと落ちるという凄い展開でしたが、Twitterでの情報収集は総じて有用でした。
定期的に国毎で検索してトレンド見ていくと、結構エンドユーザー観点でも有用なデータがプロアクティブに取れるかも知れませんね。
そのうちチャレンジしてみたいと思います。